Foundations
In this section, we will look at the basic ideas behind Generative AI (Gen AI) in simple words. We will go through the main ideas, methods, and tools that Gen AI is built on. This section is meant to give you a clear, easy understanding of the core ideas so you are ready for the more advanced topics later.
LLM stands for Large Language Model. It is a type of AI model that is trained on a huge amount of data so that it can understand and create human language. LLMs can do many different jobs, such as answering questions, writing content, writing code, summarizing text, translating languages, reasoning, and having normal conversations.
GPT stands for Generative Pre-trained Transformer. Let’s look at each word one by one.
- Generative: It can create new content based on what you give it. This means it can write text, code, or other content that did not exist before.
- Pre-trained: How does it create this content? It uses the knowledge it picked up during training. It was trained on a huge amount of text from the internet, books, articles, and other sources. Because of this training, it learns grammar, facts, how to reason, and even some basic common sense.
- Transformer: It is built using the transformer architecture, a type of neural network that is very good at working with sequences of data, like text. In simple words, think of a transformer as a black box. You give it some input text, and it gives you an output by understanding how the different parts of that input are connected to each other.
How GPT Works?
Section titled “How GPT Works?”When you type a prompt or question like What is the capital of France?, the text is first changed into tokens, and then sent to the Transformer (LLM) for processing. The model guesses the next token based on the input and what it learned during training. It keeps guessing tokens one after another until the full answer is ready. At the end, detokenization changes those tokens back into normal, readable text.
The diagram below shows step by step how GPT builds a response from a prompt:
First, let’s understand why tokens are needed.
As we know, computers are very good at handling numbers, but they cannot understand human language on their own. To fix this, text must first be changed into something a computer can work with. This is where tokens come in.
A token is a small piece of text that an LLM can understand and process. In simple words, a token can be a single character, a full word, part of a word, a punctuation mark, or even a special symbol. Each token is given its own ID number, called a token ID, which the model uses internally.
Tokens are usually grouped into four types:
- Word Tokens: These are full words treated as a single token. For example, the word
"cat"is one token. - Subword Tokens: These are smaller pieces of a word treated as separate tokens. For example, the word
"unhappiness"might be split into"un","happi", and"ness". - Character Tokens: These are single letters treated as separate tokens. For example, the word
"cat"would be split into"c","a", and"t". - Special Tokens: These are tokens used for specific jobs, such as marking the end of a sentence, filling empty space (padding), or giving the model special instructions.
Want to see what tokens actually look like? You can check this site: https://tiktokenizer.vercel.app/
Different LLMs break text into tokens in different ways, so the same sentence might be split differently depending on which model you use.
Tokenization
Section titled “Tokenization”Tokenization is the process of turning normal text into tokens so that an LLM can understand and work with it.
For example:
I love programming.might be turned into:
["I", " love", " programming", "."]Each token then gets its own unique ID number. This lets the model work with numbers instead of plain text, since that is how computers handle information internally.
Detokenization
Section titled “Detokenization”Detokenization is the opposite of tokenization.
After the model creates a response as a list of tokens, detokenization joins those tokens back together into normal, readable text.
For example:
["I", " love", " programming", "."]becomes:
I love programming.This is the final text that you actually see as the model’s answer.
Code Example Using tiktoken
Section titled “Code Example Using tiktoken”First, install the tiktoken library, which is a fast tokenizer.
pip install tiktokenNow you can use this code to see how tokenization and detokenization actually work:
import tiktoken
encoder = tiktoken.encoding_for_model("gpt-4.0")
text = "Hello world, welcome to LLMs!"
# Tokenizationtokens = encoder.encode(text)print("Tokens:", tokens)
# Detokenizationdecoded_text = encoder.decode(tokens)print("Decoded Text:", decoded_text)Vector Embeddings
Section titled “Vector Embeddings”First, let’s understand why vector embeddings are needed.
As we said earlier, computers work with numbers, not meanings. Tokenization turns text into token IDs, but those IDs are just numbers. They don’t tell the model anything about what the words actually mean.
This is where vector embeddings come in.
A vector embedding is a way of turning words, tokens, images, or other data into a list of numbers that represents their meaning. These numbers help the model understand how different pieces of data are related to each other.
In simple words, embeddings help the model understand that some words are more closely related to each other than others.
For example, look at these words:
DogCatPythonJavaScriptThe model learns that Dog and Cat are closely related because both are animals. In the same way, Python and JavaScript are closely related because both are programming languages.
Because of this, their embeddings become more similar to each other than to words that are not related.
Embeddings also help the model understand connections between ideas. For example, if the model often sees sentences such as:
Delhi is the capital of India.Paris is the capital of France.It learns that Delhi is connected to India in the same way that Paris is connected to France.
This ability to capture meaning and connections is what makes embeddings so useful. They help AI models understand context, find related information, do semantic search, and give more meaningful answers.
To see embeddings shown visually, check this tool: TensorFlow Embedding Projector: https://projector.tensorflow.org/
Positional Encoding
Section titled “Positional Encoding”First, let’s understand why positional encoding is needed.
Transformers process all tokens at the same time, in parallel. This makes them very fast and efficient, but it also means they don’t naturally know the order of the words in a sentence.
This is a problem because the meaning of a sentence often depends on the order of the words.
For example:
The dog chased the cat.and
The cat chased the dog.use the exact same words, but they mean completely different things because the words are in a different order.
This is where positional encoding comes in.
Positional encoding is a method used to tell the transformer where each token sits in the input sequence. It adds position information to the token’s embedding so the model knows where each token appears in the sentence.
For example, in the sentence:
I love programmingthe model does not only see the tokens:
Iloveprogrammingit also knows their positions:
I is at Position 1love is at Position 2programming is at Position 3By combining a token’s meaning (its embedding) with its position, the transformer can understand both what the token means and where it sits in the sentence.
This helps the model understand sentence structure, how words relate to each other, and the overall meaning of the text.
Self-Attention Mechanism
Section titled “Self-Attention Mechanism”First, let’s understand why self-attention is needed.
In a sentence, the meaning of a word often depends on the other words around it. The same word can mean different things depending on the situation.
For example:
River bankICICI bankIn the first example, bank means the side of a river. In the second example, bank means a financial institution. The meaning of the word changes depending on the words around it.
This is where the self-attention mechanism comes in.
Self-attention lets the model look at all the other words in a sentence while it is processing one particular word. By checking the surrounding words, the model can better understand the correct meaning and context of that word.
For example, when the model processes the word bank in:
The fisherman sat near the river bank.it pays more attention to words like river and fisherman, which help it understand that bank here means the side of a river.
In simple words, self-attention helps the model figure out which words matter most for understanding a particular word. It lets the model find connections between words, understand context, and give more accurate answers.
Multi-Head Attention
Section titled “Multi-Head Attention”First, let’s understand why multi-head attention is needed.
As we learned, self-attention helps the model understand how words in a sentence are connected. But a single sentence can have many different types of connections happening at the same time.
For example, look at this sentence:
The programmer who built the website fixed the bug.To fully understand this sentence, the model may need to focus on several things at once:
- The connection between programmer and built.
- The connection between website and built.
- The connection between programmer and fixed.
- The connection between bug and fixed.
Looking at only one connection at a time may not give the full meaning of the sentence.
This is where multi-head attention comes in.
Multi-head attention lets the model run several self-attention operations at the same time. Each attention head can focus on a different part of the sentence and learn a different type of connection between words.
For example, one attention head might focus on:
programmer to builtwhile another attention head focuses on:
website to builtand another focuses on:
bug to fixedEach head learns a different angle of the sentence. The results from all the heads are then combined to build a richer understanding of the text.
In simple words, self-attention is like having one person study a sentence, while multi-head attention is like having several people study the same sentence from different angles and then putting all their findings together.
This helps the model understand context, connections, grammar, and meaning better, which leads to more accurate predictions and responses.
Linear and Softmax Layers
Section titled “Linear and Softmax Layers”Linear Layer
Section titled “Linear Layer”A Linear Layer in a Transformer is a neural network layer that turns the processed information into numerical scores. It helps the model decide which token could come next.
The linear layer takes the output from the attention layers and creates a score for every possible next token.
These scores are called:
- raw scores
- logits
They are not probabilities yet, just numbers.
Softmax Layer
Section titled “Softmax Layer”Softmax is a math function that turns the raw scores from the linear layer into probabilities.
It makes sure all the values are:
- between 0 and 1
- adding up to 100%
This helps the model understand which token is most likely to be the next one.
How They Work Together
Section titled “How They Work Together”Let’s say the model is processing:
"I am"After the Linear Layer, the scores look like this:
doing -> 8.5happy -> 5.2fine -> 7.1running -> 2.4These are just raw scores.
After the Softmax Layer, they are turned into probabilities:
doing -> 70%fine -> 20%happy -> 8%running -> 2%Now the model can choose the most likely next token.
Final prediction:
"I am doing"Linear Layer: creates scores for the possible next tokens.
Softmax: turns those scores into probabilities.
Transformer
Section titled “Transformer”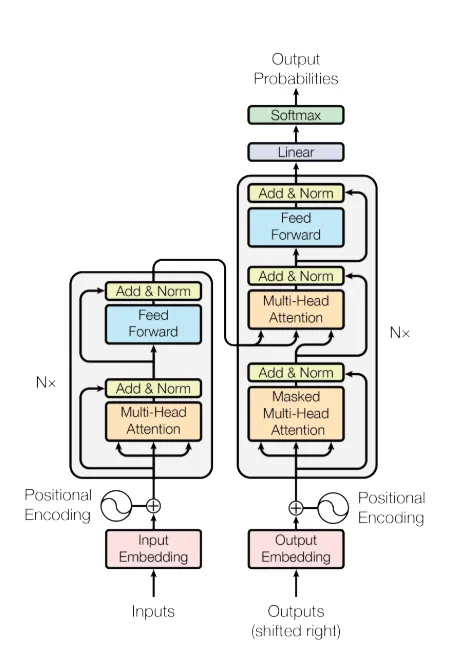
A Transformer is a deep learning structure that powers modern AI systems and Large Language Models (LLMs). It works with text in the form of tokens rather than full sentences, and it is built to understand how words relate to each other and to produce meaningful output.
The most important part of the Transformer architecture is the Attention Mechanism, especially Self-Attention. Self-attention lets the model understand how different words in a sentence are connected and which words matter most in a given situation.
For example, in the sentence:
The animal didn't cross the road because it was tired.the model can work out that the word “it” refers to “animal”.
Unlike older models such as RNNs, Transformers can process many tokens at the same time instead of reading them one by one. This makes them faster, more efficient, and better at understanding long pieces of text.
Because of these strengths, Transformers became the base for modern AI systems such as GPT, Gemini, Claude, and many other LLMs.
Transformer Architecture
Section titled “Transformer Architecture”The Transformer architecture was introduced in the well known Google research paper called “Attention Is All You Need”.
A Transformer processes text in a few steps.
First, the input text is turned into tokens. These tokens are then turned into embeddings, which are number based representations that capture their meaning.
Next, positional encoding is added so the model knows the order of the words in the sentence.
The core part of the Transformer is multi-head attention, which lets the model focus on different parts of the input and understand how words relate to each other. This helps the model understand context and meaning more clearly.
The original Transformer architecture has two main parts:
- Encoder: reads and understands the input.
- Decoder: generates the output sequence.
However, many modern LLMs such as GPT use only the Decoder part of the Transformer architecture.
While generating text, the model predicts one token at a time, based on the input and the tokens it has already generated.
For example:
Input:"Hey there, how are you?"
Generated Output:"I"-> "I am"-> "I am doing"-> "I am doing fine"After each prediction, the new token is added to the context, and this process repeats until the response is complete.
At the end, the model works out the probability of every possible next token, and the most likely one is picked and added to the output.